Research Overview Video
(As of Mar 2023 in Korean)
Current Research Projects
Real-Time Audio-Visual Music Information Processing for Interactive AI Performance System
This project is supported by the National Research Foundation of Korea grant (2023-2027)
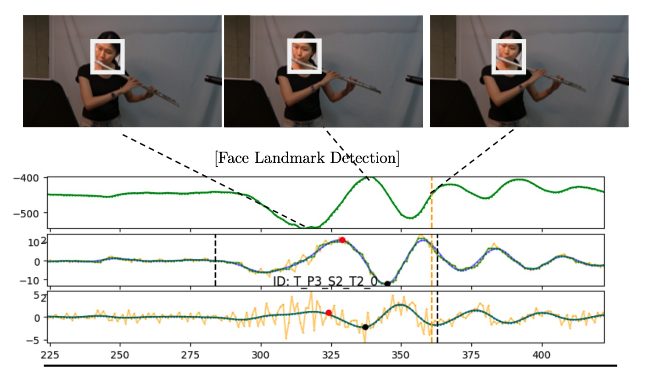

Expressive Performance Control
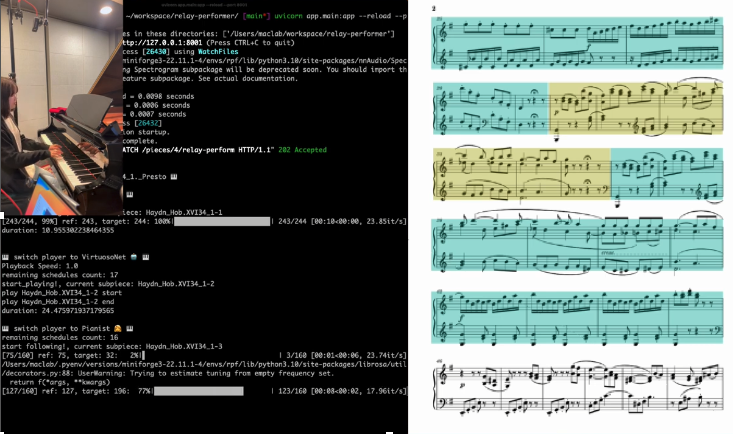
Multimodal Piano Performance Dataset Collection and Motion Generation
This project is supported by Yamaha (2023-2026)
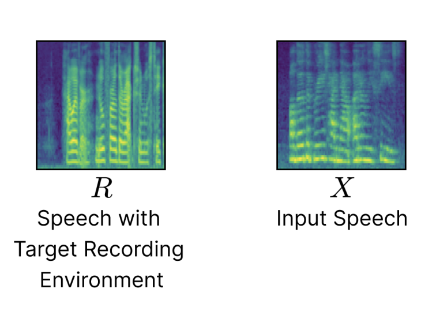
Neural Audio Processing and Synthesis
This project is supported by the National Research Foundation of Korea grant (2023-2026)
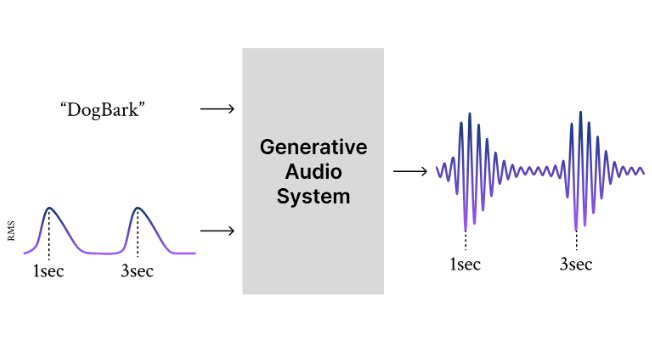
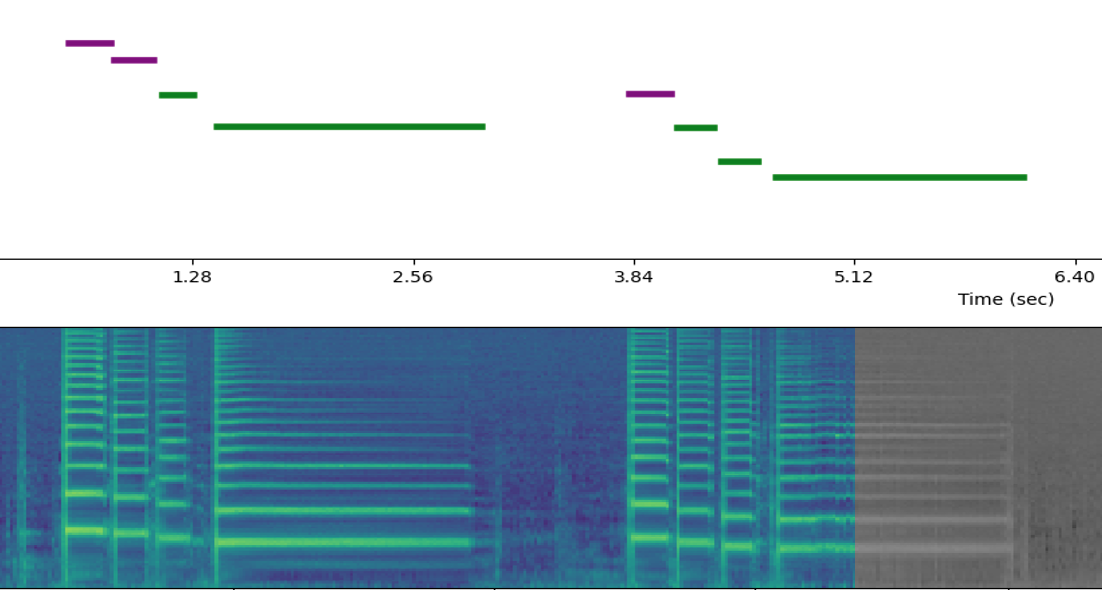
Intelligent Music Production

AI DJ, Music Structure Analysis
DJ mix Analysis, Automatic Mix Generation, Beat-tracking, Music Structure Analysis
More

Semantic Music and Audio Understanding
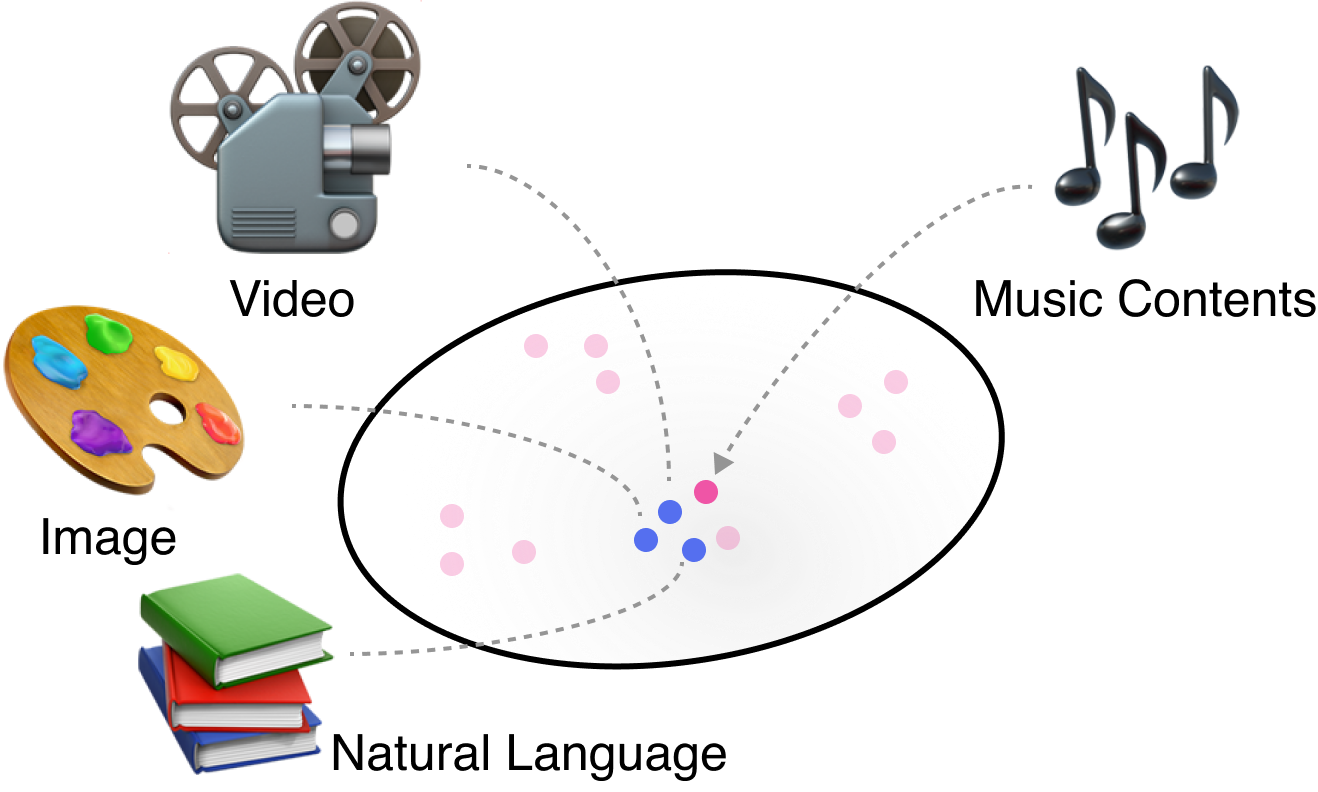
Multimodal Music Retrieval
Multimodal Representation Learning, Joint Embedding, Zero-Shot Learning
More

Acoustic Scene and Event Understanding
Soundscape, DCASE
Symbolic Music Processing
Korean Traditional Music

Expression Analysis
Haegum Expression Analysis and Notation, Gayagum Vibrato Analysis
Past Research Archives
Music Tagging & Rertrieval and Representation Learning

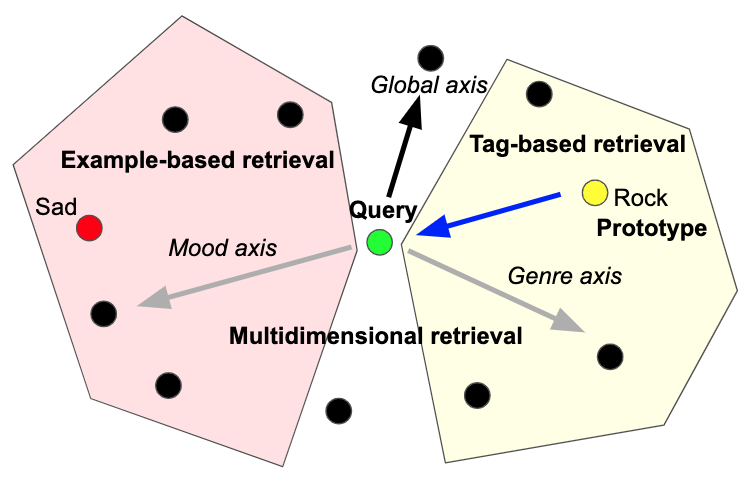
Deep Audio Embedding Learning
Disentangled Representation Learning, Representation Learning with Meta Data
More
Singing Melody Extraction and Transcription
Piano Music Transcription and Expressive Performance Rendering

Singing Voice Synthesis and Conversion

Address: 291 Daehak-ro, Yuseong-gu, Daejeon (34141)
N25 #3236, KAIST, South Korea