Controllable Multimodal Audio Generation
Main Contributors: Junwon Lee, Yoonjin Chung, Jaekwon Im
Objective: Controllable Audio Generation with Multimodal Conditioning for Multimedia Applications.
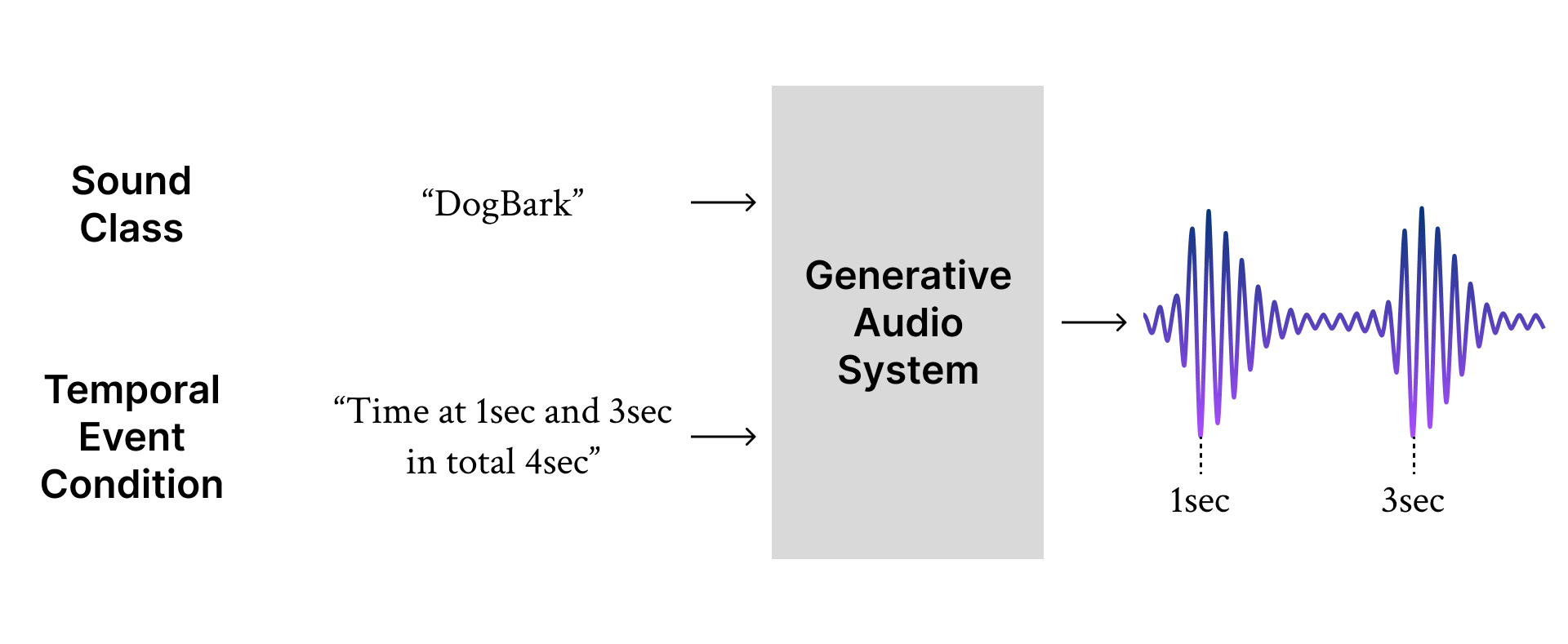
Table of Contents:
Background: Foley Sound Generation
Topic 1: Audio Generation Models with Multimodal Conditioning
Topic 2: Evaluating Audio Generation Models
Background: Foley Sound Generation
Foley sound effects play a crucial role in enhancing immersion across media such as film, games, and virtual reality. By adding depth and authenticity, they create a more engaging and captivating auditory experience. Foley is the replication of everyday sound effects, added in post-production to film, video, and other media to enhance audio quality. Named after Jack Foley, a pioneering sound-effects artist, Foley sounds include common noises such as footsteps, the rustle of clothing, creaking doors, and breaking glass. Foley artists manually produce and synchronize these sounds with visual elements, recreating specific effects to augment or replace original recordings. This work takes place on specialized Foley stages or in studios equipped with props and sets designed to achieve the desired acoustics (bottom-left figure [2][3][4]).

The creation of Foley sounds is intricate and time-consuming, involving the capture of numerous subtle effects within a video sequence. Automated Foley Sound Synthesis focuses on generating audio that:
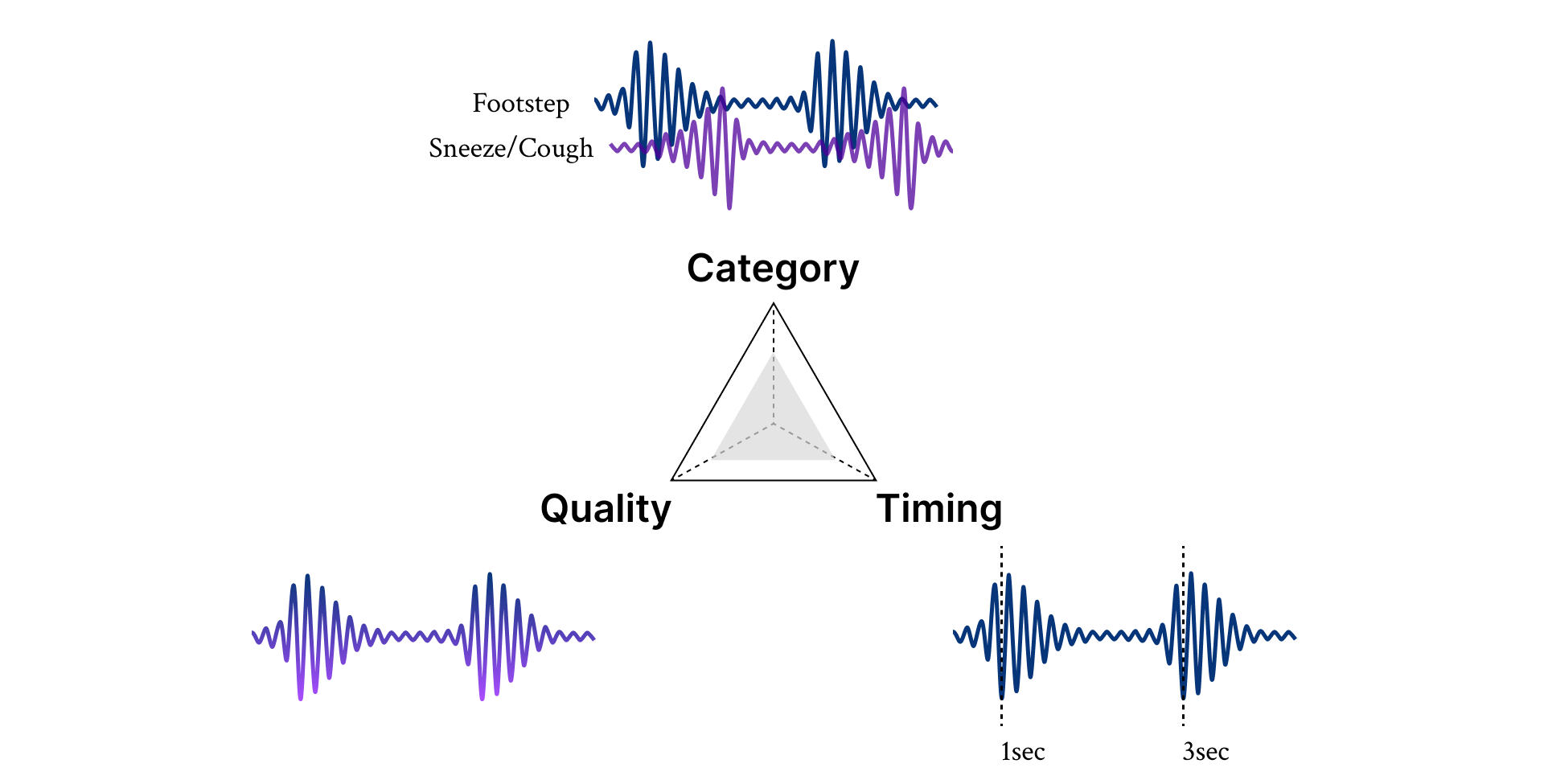
- represents specific sound sources with the desired nuance and timbre (semantic control).
- aligns temporally with events or patterns in the visual content (temporal control).
- maintains high overall quality (quality control).
For instance, given a video, the system should differentiate between the sounds of a whining Chihuahua and a barking Retriever, identify whether a raindrop hits a glass window or a wooden surface, and vary the timing and volume of footsteps.
Topic 1: Audio Generation Models with Multimodal Conditioning
Our projects center on Controllable Foley sound synthesis, aimed at enabling easy and intuitive production. The objective is to empower users to control the sound source(s) and temporal events during neural audio generation.
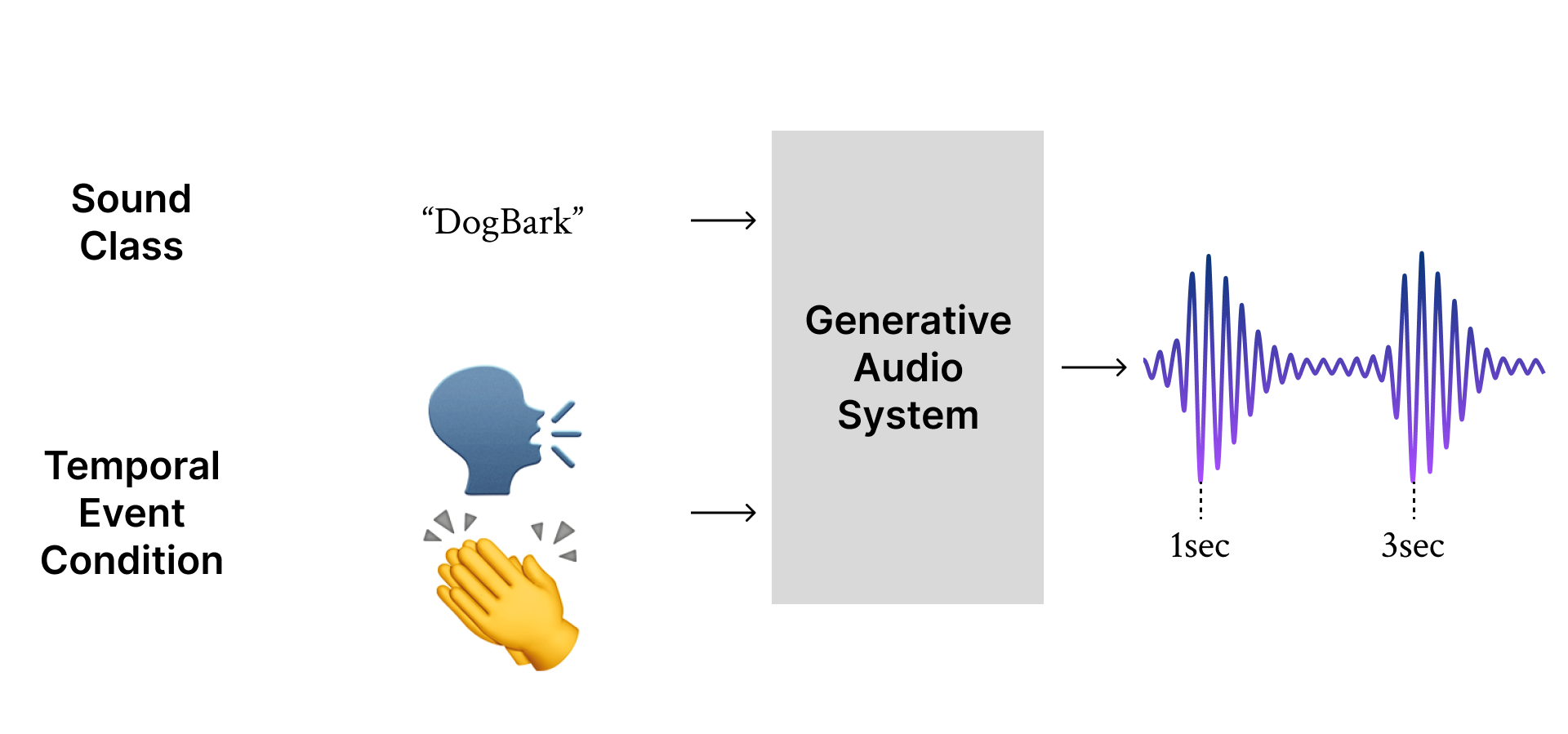
T-Foley represents our initial advancement in this field: along with the desired sound class, the user provides the timing and volume of the desired sound events via a reference sound (e.g., vocal mimicry or a clap). The model extracts temporal event features (i.e., the RMS of the waveform) from the reference sound and uses them as conditioning input for generation.
Video-Foley is a framework for automated Video-to-Audio (V2A) generation. The temporal feature (i.e., RMS) is predicted from the video input. A pre-trained Text-to-Audio (T2A) model is fine-tuned to take both the temporal feature and a text prompt as conditioning inputs for generation.

SelVA (Selective Video-to-Audio Generation) is the first work to realize track-level audio generation rather than holistic audio generation. Along with video input, the user specifies a target sound source via a text prompt. A specialized video encoder extracts a feature representation of the target sound source, which is then used as a conditioning input for audio generation.

Related Publications
-
Hear What Matters! Text-conditioned Selective Video-to-Audio Generation
Junwon Lee, Juhan Nam, and Jiyoung Lee
arXiv preprint, 2025
[paper] [code] [demo] -
Video-Foley: Two-Stage Video-To-Sound Generation via Temporal Event Condition For Foley Sound
Junwon Lee, Jaekwon Im, Dabin Kim, and Juhan Nam
IEEE/ACM Transactions on Audio, Speech and Language Processing, 2025
[paper] [code] [demo] -
T-foley: A Controllable Waveform-domain Diffusion Model for Temporal-event-guided Foley Sound Synthesis
Yoonjin Chung*, Junwon Lee*, and Juhan Nam
Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024
[paper] [code] [demo]
Topic 2: Evaluating Audio Generation Models
As audio generation models become more capable, it is crucial to evaluate their performance across multiple dimensions. In particular, automatic evaluation metrics that align with human perception are essential for the field’s progress.
Objective Evaluation Metrics
A widely used automatic evaluation metric for overall audio quality is Fréchet Audio Distance (FAD). However, it has three critical limitations: (1) it is distribution-dependent, (2) it is biased by sample size, and (3) it is computationally expensive. To address these limitations, we propose an effective and efficient alternative, Kernel Audio Distance (KAD), which leverages Maximum Mean Discrepancy (MMD).

Organizing DCASE Challenge
We contribute to the advancement of practical research directions and the development of suitable evaluation methodologies by helping host the DCASE Challenge. Our initial focus was on the "Foley Sound Synthesis" task, which aimed to generate natural and high-quality audio for specific Foley sound categories. More recently, our efforts have shifted to "Sound Scene Synthesis," focusing on integrating general sound scenes for standard sound post-production workflows. For more information, please visit the official DCASE website.
DCASE 2023 Challenge Task7 Foley Sound Synthesis
DCASE 2024 Challenge Task7 Sound Scene Synthesis
 DCASE 2023 Challenge Task 7
DCASE 2023 Challenge Task 7 Foley Sound Synthesis
 DCASE 2024 Challenge Task 7
DCASE 2024 Challenge Task 7 Sound Scene Synthesis
Related Publications
-
KAD: No More FAD! An Effective and Efficient Evaluation Metric for Audio Generation
Yoonjin Chung, Pilsun Eu, Junwon Lee, Keunwoo Choi, Juhan Nam, Ben Sangbae Chon
Workshop on Machine Learning for Audio, International Conference on Machine Learning (ICML), 2025
[paper] -
Challenge on Sound Scene Synthesis: Evaluating Text-to-Audio Generation
Junwon Lee*, Modan Tailleur*, Laurie M. Heller*, Keunwoo Choi*, Mathieu Lagrange*, Brian McFee, Keisuke Imoto, Yuki Okamoto
Audio Imagination: NeurIPS Workshop AI-Driven Speech, Music, and Sound Generation, 2024
[paper] -
Correlation of Fréchet Audio Distance With Human Perception of Environmental Audio Is Embedding Dependant
Modan Tailleur*, Junwon Lee*, Mathieu Lagrange, Keunwoo Choi, Laurie M. Heller, Keisuke Imoto, and Yuki Okamoto
32nd European Signal Processing Conference (EUSIPCO), 2024
[paper] -
Foley sound synthesis at the DCASE 2023 challenge
Keunwoo Choi*, Jaekwon Im*, Laurie Heller*, Brian McFee, Keisuke Imoto, Yuki Okamoto, Mathieu Lagrange, and Shinosuke Takamichi
Workshop on detection and classification of acoustic scenes and events (DCASE), 2023
[paper]
References
- [1] Keunwoo Choi, Jaekwon Im, Laurie Heller, Brian McFee, Keisuke Imoto, Yuki Okamoto, Mathieu Lagrange, and Shinosuke Takamichi, “Foley sound synthesis at the DCASE 2023 challenge,” Workshop on detection and classification of acoustic scenes and events (DCASE). 2023.
- [2] Ghose, Sanchita, and John Jeffrey Prevost. "Autofoley: Artificial synthesis of synchronized sound tracks for silent videos with deep learning." IEEE Transactions on Multimedia 23 (2020): 1895-1907.
- [3] https://theartcareerproject.com/careers/foley-art/
- [4] https://beatproduction.net/foley-sfx-pack/