End-to-End Neural Singing Voice Synthesis
Main Contributor: Soonbeom Choi
Singing Voice Synthesis (SVS) is a task that generates vocal sounds from melody and lyrics on computers. It has a long history dating back to the digitized vocal-tract analog model used to synthesize the song "Daisy Bell (Bicycle Built for Two)" in 1961. Since then, reseachers have made great efforts to imitate natural human singing voice. This research aims to explore various topics in SVS including high-quality audio generation, controllabe vocal expressions, and multilingual singing voice synthesis.

Singing Voice Synthesis
Children's Song Dataset for Singing Voice Research
"Children's Song Dataset (CSD)" an open-source dataset for singing voice research. The dataset contains 50 Korean and 50 English songs sung by one Korean female professional pop singer. Each song is recorded with two separate keys and each audio recording is paired with transcribed MIDI and lyrics annotations with time alignment.
Related Publications
-
Children’s Song Dataset for Singing Voice Research
Soonbeom Choi, Wonil Kim, Saebyul Park, Sangeon Yong, and Juhan Nam
Late-Breaking Demo in the 21th International Society for Music Information Retrieval Conference (ISMIR). [paper] [website] [repository]
End-to-End Singing Voice Synthesis
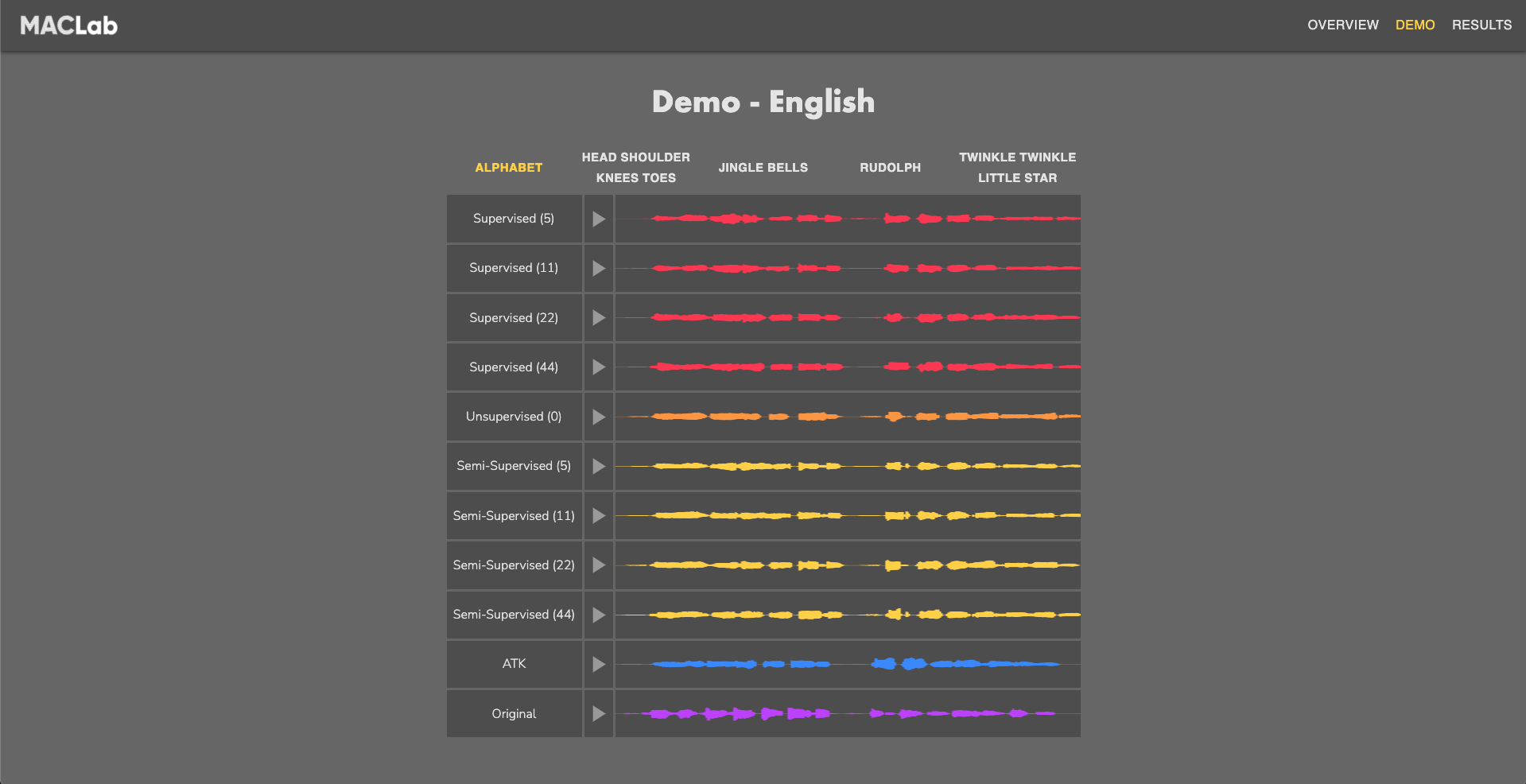
We have developed end-to-end SVS models which generate singing voice only using melody and lyrics input using deep neural networks and the CSD dataset. This demo shows our recent results from a melody-unsupervised singing voice synthesis model.
Related Publications
-
A Melody-Unsupervision Model for Singing Voice Synthesis
Soonbeom Choi and Juhan Nam
Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022 [paper] [website]
-
Korean Singing Voice Synthesis Based on Auto-Regressive Boundary Equilibrium GAN
Soonbeom Choi, Wonil Kim, Saebyul Park, Sangeon Yong, and Juhan Nam
Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020 [paper] [website] [code]
Ongoing Work
End-to-end SVS systems have achieved remarkable results in terms of sound quality and naturalness. However, they are not flexible to control various voice expressions and are limited to a single language of lyrics. We are currently working on SVS models to tackle these issues.